
설계
1. 현재 대전지역에서 모집중인 공고를 10페이지까지 불러온다
2. 불러온 결과를 엑셀로 저장한다.
3. 페이지와 연동하여 데이터가 갱신된다.
코드
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
import csv
driver = webdriver.Chrome()
url = "https://www.saramin.co.kr/zf_user/jobs/list/domestic?loc_mcd=105000&panel_type=&search_optional_item=n&search_done=y&panel_count=y&preview=y"
driver.get(url)
time.sleep(2)
comps = driver.find_elements(By.CLASS_NAME, 'list_item')
file = open('data/saramin.csv', 'w', newline = '')
writer = csv.writer(file)
pages = driver.find_element(By.XPATH,'//*[@id="default_list_wrap"]/div')
pages = pages.find_elements(By.TAG_NAME, 'button')
for i in range(2, len(pages)+1):
comps = driver.find_elements(By.CLASS_NAME, 'list_item')
for row in comps:
temp = []
try:
comp = row.find_element(By.TAG_NAME, 'a').text
title = row.find_element(By.CLASS_NAME, 'job_tit')
title = title.find_element(By.TAG_NAME, 'a').text
jobs = row.find_element(By.CLASS_NAME, 'job_sector').text
jobs = jobs.replace('\n', '')
locs = row.find_element(By.CLASS_NAME, 'recruit_info').text
locs = locs.replace('\n', ', ')
temp.append(comp)
temp.append(title)
temp.append(jobs)
temp.append(locs)
writer.writerow(temp)
print(comp, title, jobs, locs)
except:
continue
if i != 11:
driver.find_element(By.XPATH, '//*[@id="default_list_wrap"]/div/button'+'['+str(i)+']').click()
time.sleep(3)
file.close()
실행
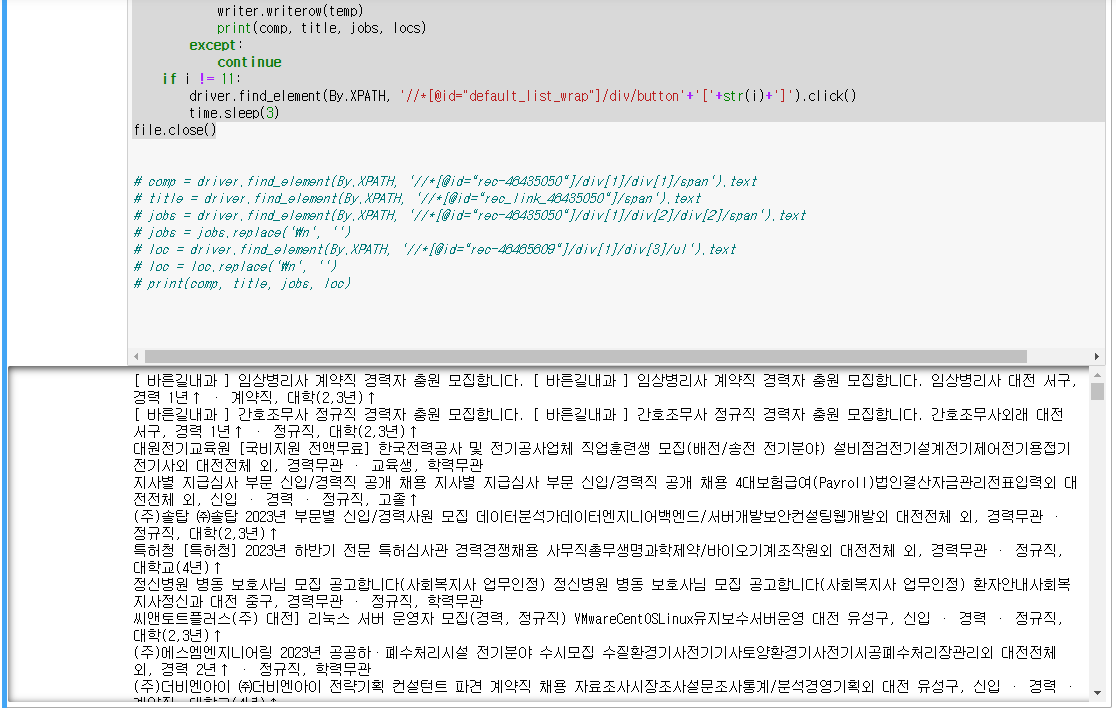


 0123
0123
마무리
파이썬을 이용한 간단한 사람인 웹크롤링이다.
반응형
'IT > Python' 카테고리의 다른 글
| [Python] 쇼핑몰 이미지 크롤링 (30) | 2023.09.14 |
|---|---|
| [Python] 대통령 연설문 크롤링 (0) | 2023.09.13 |
| [Python] 바이오리듬 (30) | 2023.09.10 |
| [Python] 글에 사용된 단어 수 세기 (0) | 2023.09.09 |
| [Python] 이름 자동생성 (1) | 2023.09.07 |