IT/Python
[Python] 대통령 연설문 크롤링
잿호
2023. 9. 13. 21:44
설계
1. 대통령 기록관 사이트에서 연설문을 크롤링해온다
2. 크롤링해온 연설문 내용은 txt파일로 저장한다
3. txt파일은 [이름][년도].txt로 data_speech 폴더에 저장된다.
코드
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
from collections import Counter
from konlpy.tag import Okt
import matplotlib
import matplotlib.font_manager as fm
font_location = 'C:/Windows/Fonts/H2GTRE.TTF'
font_name = fm.FontProperties(fname=font_location).get_name()
matplotlib.rc('font',family=font_name)
driver = webdriver.Chrome()
url = "https://www.pa.go.kr/research/contents/speech/index.jsp"
driver.get(url)
time.sleep(3)
driver.find_element(By.XPATH, '//*[@id="speechEvent"]/option[8]').click()
driver.find_element(By.XPATH, '//*[@id="frm"]/fieldset[1]/div[2]/div[5]/button[2]').click()
time.sleep(3)
driver.find_element(By.XPATH, '//*[@id="m-items2"]/li[2]/a').click()
time.sleep(3)
speechs = []
pages = len(driver.find_elements(By.XPATH, '//*[@id="frm"]/nav[2]/ul/li'))
for i in range(3, pages-1):
trs = driver.find_elements(By.XPATH, '//*[@id="M_More"]/tr')
for row in range(1, len(trs)+1):
name = driver.find_element(By.XPATH, '//*[@id="M_More"]/tr['+str(row)+']/td[2]/a').text
title = driver.find_element(By.XPATH, '//*[@id="M_More"]/tr['+str(row)+']/td[5]/a').text
date = driver.find_element(By.XPATH, '//*[@id="M_More"]/tr['+str(row)+']/td[6]').text
driver.find_element(By.XPATH, '//*[@id="M_More"]/tr['+str(row)+']/td[5]/a').click()
time.sleep(2)
contents = driver.find_element(By.XPATH, '//*[@id="content"]/div/table/tbody/tr[4]/td').text
driver.back()
temp = []
temp.append(name)
temp.append(title)
temp.append(date)
temp.append(contents)
speechs.append(temp)
try:
driver.find_element(By.XPATH, '//*[@id="frm"]/nav[2]/ul/li[4]/a').click()
except:
continue
print('크롤링 완료')
after_sp = []
for i in range(len(speechs)-1):
if speechs[i][2][:4] == speechs[i+1][2][:4]:
speechs[i]
else:
after_sp.append(speechs[i])
after_sp.append(speechs[len(speechs)-1])
for row in after_sp:
file = open('data_speech/' + row[0] + row[2][:4] + '.txt', 'w')
file.write(row[3])
file.close()
print('저장을 완료 했습니다.')
실행


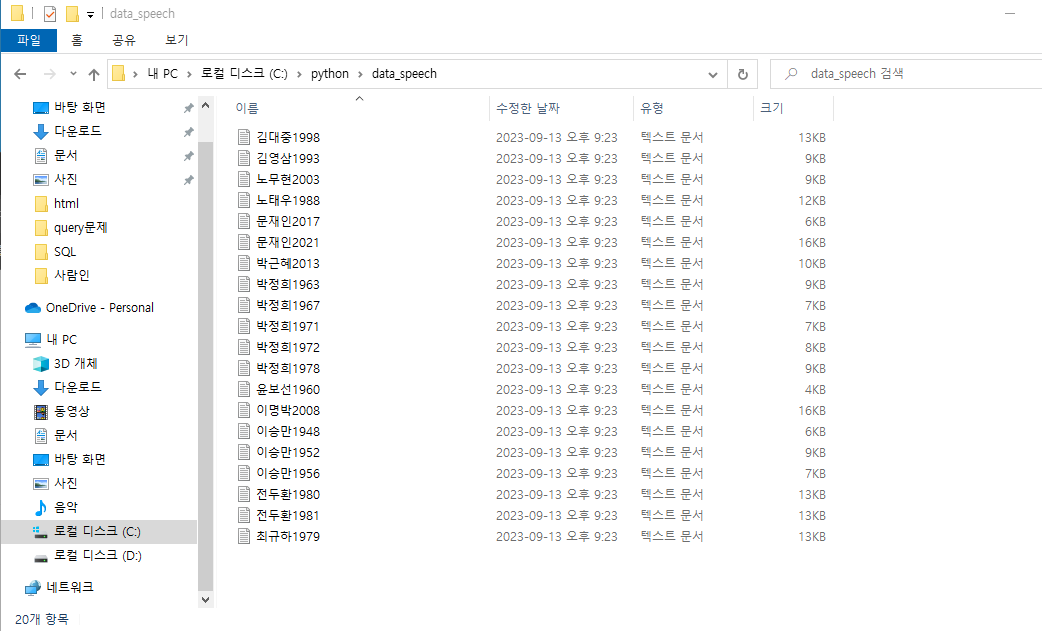 012
012
마무리
다음 포스팅에서는 크롤링해온 연설문 파일들을 응용하여 다른 코드를 작성해보겠습니다.
반응형